- 28
- 08月
This is the fourteenth article in the series in which I document my experience writing web applications in Python using the Flask microframework.
The goal of the tutorial series is to develop a decently featured microblogging application that demonstrating total lack of originality I have decided to call microblog.
Here is an index of all the articles in the series that have been published to date:
- Part I: Hello, World!
- Part II: Templates
- Part III: Web Forms
- Part IV: Database
- Part V: User Logins
- Part VI: Profile Page And Avatars
- Part VII: Unit Testing
- Part VIII: Followers, Contacts And Friends
- Part IX: Pagination
- Part X: Full Text Search
- Part XI: Email Support
- Part XII: Facelift
- Part XIII: Dates and Times
- Part XIV: I18n and L10n (this article)
- Part XV: Ajax
- Part XVI: Debugging, Testing and Profiling
The topics of today's article are Internationalization and Localization, commonly abbreviated I18n and L10n. We want our microblog application to be used by as many people as possible, so we can't forget that there is a lot of people out there that can't speak English, or that can, but prefer to speak their native language.
To make our application accessible to foreign visitors we are going to use the Flask-Babel extension, which provides an extremely easy to use framework to translate the application into different languages.
If you haven't installed Flask-Babel yet, then this is the time to do it. For Linux and Mac users:
flask/bin/pip install flask-babel
And for Windows users:
flask\Scripts\pip install flask-babel
Configuration
Flask-Babel is initialized simply by creating an instance of class Babel and passing the Flask application to it (file app/__init__.py):
from flask.ext.babel import Babel
babel = Babel(app)
We also need to decide which languages we will offer translations for. For now we'll start with a Spanish version, since we have a translator at hand (your truly), but it'll be easy to add more languages later. The list of supported languages will go to our configuration (file config.py):
# -*- coding: utf-8 -*-
# ...
# available languages
LANGUAGES = {
'en': 'English',
'es': 'Espa?ol'
}
The LANGUAGES dictionary has keys that are the language codes for the available languages, and values that are the printable name of the language. We are using the short language codes here, but when necessary the long codes that specify language and region can be used as well. For example if we wanted to support American and British English as separate languages we would have 'en-US' and 'en-GB' in our dictionary.
Note that because the word Espa?ol has a foreign character in it we have to add the coding comment at the top of the Python source file, to tell the Python interpreter that we are using the UTF-8 encoding and not ASCII, which lacks the ? character.
The next piece of configuration that we need is a function that Babel will use to decide which language to use (file app/views.py):
from app import babel
from config import LANGUAGES
@babel.localeselector
def get_locale():
return request.accept_languages.best_match(LANGUAGES.keys())
The function that is marked with the localeselector decorator will be called before each request to give us a chance to choose the language to use when producing its response. For now we will do something very simple, we'll just read the Accept-Languages header sent by the browser in the HTTP request and find the best matching language from the list that we support. This is actually pretty simple, the best_match method does all the work for us.
The Accept-Languages header in most browsers is configured by default with the language selected at the operating system level, but all browsers give users the chance to select other languages. Users can provide a list of languages, each with a weight. As an example, here is a complex Accept-Languages header:
Accept-Language: da, en-gb;q=0.8, en;q=0.7
This says that Danish is the preferred language (with default weight = 1.0), followed by British English (weight = 0.8) and as a last option generic English (weight = 0.7).
The final piece of configuration that we need is a Babel configuration file that tells Babel where to look for texts to translate in our code and templates (file babel.cfg):
[python: **.py]
[jinja2: **/templates/**.html]
extensions=jinja2.ext.autoescape,jinja2.ext.with_
The first two lines give Babel the filename patterns for our Python and template files respectively. The third line tells Babel to enable a couple of extensions that make it possible to find text to translate in Jinja2 templates.
Marking texts to translate
Now comes the most tedious aspect of this task. We need to review all our code and templates and mark all English texts that need translating so that Babel can find them. For example, take a look at this snippet from function after_login:
if resp.email is None or resp.email == "":
flash('Invalid login. Please try again.')
redirect(url_for('login'))
Here we have a flash message that we want to translate. To expose this text to Babel we just wrap the string in Babel's gettext function:
from flask.ext.babel import gettext
# ...
if resp.email is None or resp.email == "":
flash(gettext('Invalid login. Please try again.'))
redirect(url_for('login'))
In a template we have to do something similar, but we have the option to use _() as a shorter alias to gettext(). For example, the word Home in this link from our base template:
<li><a href="{{ url_for('index') }}">Home</a></li>
can be marked for translation as follows:
<li><a href="{{ url_for('index') }}">{{ _('Home') }}</a></li>
Unfortunately not all texts that we want to translate are as simple as the above. As an example of a tricky one, consider the following snippet from our post.html subtemplate:
<p><a href="{{url_for('user', nickname = post.author.nickname)}}">{{post.author.nickname}}</a> said {{momentjs(post.timestamp).fromNow()}}:</p>
Here the sentence that we want to translate has this structure: "<nickname> said <when>:". One would be tempted to just mark the word "said" for translation, but we can't really be sure that the order of the name and the time components in this sentence will be the same in all languages. The correct thing to do here is to mark the entire sentence for translation using placeholders for the name and the time, so that a translator can change the order if necessary. To complicate matters more, the name component has a hyperlink embedded in it!
There isn't really a nice and easy way to handle cases like this. The gettext function supports placeholders using the syntax %(name)s and that's the best we can do. Here is a simple example of a placeholder in a much simpler situation:
gettext('Hello, %(name)s', name = user.nickname)
The translator will need to be aware that there are placeholders and that they should not be touched. Clearly the name of a placeholder (what's between the %( and )s) must not be translated or else the connection to the actual value would be lost.
But back to our post template example, here is how it is marked for translation:
{% autoescape false %}
<p>{{ _('%(nickname)s said %(when)s:', nickname = '<a href="%s">%s</a>' % (url_for('user', nickname = post.author.nickname), post.author.nickname), when = momentjs(post.timestamp).fromNow()) }}</p>
{% endautoescape %}
The text that the translator will see for the above example is:
%(nickname)s said %(when)s:
Which is pretty decent. The values for nickname and when are what gives this translatable sentence its complexity, but these are given as additional arguments to the _() wrapper function and are not seen by the translator.
The nickname and when placeholders contain a lot of stuff in them. In particular, for the nickname we had to build an entire HTML link because we want this nickname to be clickable.
Because we are putting HTML in the nickname placeholder we need to turn off autoescaping to render this portion of the template, if not Jinja2 would render our HTML elements as escaped text. But requesting to render a string without escaping is considered a security risk, it is unsafe to render texts entered by users without escaping.
The text assigned to the when placeholder is safe because it is text that is entirely generated by our momentjs() wrapper function. What goes in the nickname argument, however, is coming from the nickname field of our User model, which in turn comes from our database, which can be entered by the user in a web form. If someone registers into our application with a nickname that contains embedded HTML or Javascript and then we render that malicious nickname unescaped, then we are effectively opening the door to an attacker. We certainly do not want that, so we are going to take a quick detour and remove any risks.
The solution that makes most sense is to prevent any attacks by restricting the characters that can be used in a nickname. We'll start by creating a function that converts an invalid nickname into a valid one (file app/models.py):
import re
class User(db.Model):
#...
@staticmethod
def make_valid_nickname(nickname):
return re.sub('[^a-zA-Z0-9_\.]', '', nickname)
Here we just take the nickname and remove any characters that are not letters, numbers, the dot or the underscore.
When a user registers with the site we receive his or her nickname from the OpenID provider, so we make sure we convert this nickname to something valid (file app/views.py):
@oid.after_login
def after_login(resp):
#...
nickname = User.make_valid_nickname(nickname)
nickname = User.make_unique_nickname(nickname)
user = User(nickname = nickname, email = resp.email, role = ROLE_USER)
#...
And then in the Edit Profile form, where the user can change the nickname, we can enhance our validation to not allow invalid characters (file app/forms.py):
class EditForm(Form):
#...
def validate(self):
if not Form.validate(self):
return False
if self.nickname.data == self.original_nickname:
return True
if self.nickname.data != User.make_valid_nickname(self.nickname.data):
self.nickname.errors.append(gettext('This nickname has invalid characters. Please use letters, numbers, dots and underscores only.'))
return False
user = User.query.filter_by(nickname = self.nickname.data).first()
if user != None:
self.nickname.errors.append(gettext('This nickname is already in use. Please choose another one.'))
return False
return True
With these simple measures we eliminate any possible attacks resulting from rendering the nickname to a page without escaping.
Extracting texts for translation
I'm not going to enumerate here all the changes required to mark all texts in the code and the templates. Interested readers can check the github diffs for this.
So let's assume we've found all the texts and wrapped them in gettext() or _() calls. What now?
Now we run pybabel to extract the texts into a separate file:
flask/bin/pybabel extract -F babel.cfg -o messages.pot app
Windows users should use this command instead:
flask\Scripts\pybabel extract -F babel.cfg -o messages.pot app
The pybabel extract command reads the given configuration file, then scans all the code and template files in the directories given as arguments (just app in our case) and when it finds a text marked for translation it copies it to the messages.pot file.
The messages.pot file is a template file that contains all the texts that need to be translated. This file is used as a model to generate language files.
Generating a language catalog
The next step in the process is to create a translation for a new language. We said we were going to do Spanish (language code es), so this is the command that adds Spanish to our application:
flask/bin/pybabel init -i messages.pot -d app/translations -l es
The pybabel init command takes the .pot file as input and writes a new language catalog to the directory given in the -d command line option for the language specified in the -l option. By default, Babel expects the translations to be in a translations folder at the same level as the templates, so that's where we'll put them.
After running the above comment a directory app/translations/es is created. Inside it there is yet another directory called LC_MESSAGES and inside it there is a file called messages.po. The command can be executed multiple times with different language codes to add support for other languages.
The messages.po file that is created in each language folder uses a format that is the de facto standard for language translations, the format used by the venerable gettext utility. There are many translation applications that work with .po files. For our translation needs we will use poedit, because it is one of the most popular and because it runs on all the major operating systems.
If you want to put your translator hat and give this task a try go ahead and install poedit from this link. The usage of this application is straightforward. Below is a screenshot after all the texts have been translated to Spanish:
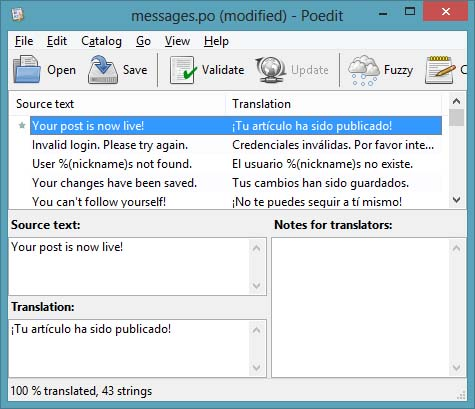
The top section shows the texts in their original and translated languages. The bottom left has a box where the translator writes the text.
Once the texts have been translated and saved back to the messages.po file there is yet another step to publish these texts:
flask/bin/pybabel compile -d app/translations
The pybabel compile step just reads the contents of the .po file and writes a compiled version as a .mo file in the same directory. This file contains the translated texts in an optimized format that can be efficiently used by our application.
The translations are now ready to be used. To check them you can modify the language settings in your browser so that Spanish is the preferred language, or if you don't feel like messing with your browser configuration you can also fake it by temporarily changing the localeselector function to always request Spanish (file app/views.py):
@babel.localeselector
def get_locale():
return "es" #request.accept_languages.best_match(LANGUAGES.keys())
Now when we run the server each time the gettext() or _() functions are called instead of getting the English text we will get the translation defined for the language returned by the localeselector function.
Updating the translations
What happens if we leave the messages.po file incomplete, with some of the texts missing a translation? Nothing happens, the application will run just fine regardless, and those texts that don't have a translation will continue to appear in English.
What happens if we missed some of the English texts in our code or templates? Any strings that were not wrapped with gettext() or _() will not be in the translation files, so they'll be unknown to Babel and remain in English. Once we spot a missing text we can add the gettext() wrapper to it and then run the following pybabel commands to update the translation files:
flask/bin/pybabel extract -F babel.cfg -o messages.pot app
flask/bin/pybabel update -i messages.pot -d app/translations
The extract command is identical to the one we issued earlier, it just generates an updated messages.pot file that adds the new texts. The update call takes the new messages.pot file and merges the new texts into all the translations found in the folder given by the -d argument.
Once the messages.po files in each language folder have been updated we can run poedit again to enter translations for the new texts, and then repeat the pybabel compile command to make those new texts available to our application.
Translating moment.js
So now that we have entered a Spanish translation for all the texts in code and templates we can run the application to see how it looks.
And right there we'll notice that all the timestamps are still in English. The moment.js library that we are using to render our dates and times hasn't been informed that we need a different language.
Reading the moment.js documentation we find that there is a large list of translations available, and that we simply need to load a second javascript with the selected language to switch to that language. So we just download the Spanish translation from the moment.js website and put it in our static/js folder as moment-es.min.js. We will follow the convention that any language file for moment.js will be added with the format moment-<language>.min.js, so that we can then select the correct one dynamically.
To be able to load a javascript that has the language code in its name we need to expose this code to the templates. The simplest way to do that is to add the language code to Flask's g global, in a similar way to how we expose the logged in user (file app/views.py):
@app.before_request
def before_request():
g.user = current_user
if g.user.is_authenticated():
g.user.last_seen = datetime.utcnow()
db.session.add(g.user)
db.session.commit()
g.search_form = SearchForm()
g.locale = get_locale()
And now that we can see the language code in the templates we can load the moment.js language script in our base template (file app/templates/base.html):
{% if g.locale != 'en' %}
<script src="/static/js/moment-{{g.locale}}.min.js"></script>
{% endif %}
Note that we make it conditional, because if we are showing the English version of the site we already have the correct texts from the first moment.js javascript file.
Lazy evaluation
While we continue playing with the Spanish version of our site we notice another problem. When we log out and try to log back in there is a flash message that reads "Please log in to access this page." in English. But where is this message? Unfortunately we aren't putting out this message, it is the Flask-Login extension that does it on its own.
Flask-Login allows this message to be configured by the user, so we are going to take advantage of that not to change the message but to make it translatable. So in our first try we do this (file app/__init__.py):
from flask.ext.babel import gettext
lm.login_message = gettext('Please log in to access this page.')
But this really does not work. The gettext function needs to be used in the context of a request to be able to produce translated messages. If we call it outside of a request it will just give us the default text, which will be the English version.
For cases like this Flask-Babel provides another function called lazy_gettext, which doesn't look for a translation immediately like gettext() and _() do but instead delay the search for a translation until the string is actually used. So here is how to properly set up the login message (file app/__init__.py):
from flask.ext.babel import lazy_gettext
lm.login_message = lazy_gettext('Please log in to access this page.')
And finally, when using lazy_gettext the pybabel extract command needs to be informed that the lazy_gettext function also wraps translatable texts with the -k option:
flask/bin/pybabel extract -F babel.cfg -k lazy_gettext -o messages.pot app
So after extracting yet another messages.pot template we update the language catalogs (pybabel update), translate the added text (poedit) and finally compile the translations one more time (pybabel compile).
And now we can say that we have a fully internationalized application!
Shortcuts
Since the pybabel commands are long and hard to remember we are going to end this article with a few quick and dirty little scripts that simplify the most common tasks we've seen above.
First a script to add a language to the translation catalog (file tr_init.py):
#!flask/bin/python
import os
import sys
if sys.platform == 'win32':
pybabel = 'flask\\Scripts\\pybabel'
else:
pybabel = 'flask/bin/pybabel'
if len(sys.argv) != 2:
print "usage: tr_init <language-code>"
sys.exit(1)
os.system(pybabel + ' extract -F babel.cfg -k lazy_gettext -o messages.pot app')
os.system(pybabel + ' init -i messages.pot -d app/translations -l ' + sys.argv[1])
os.unlink('messages.pot')
Then a script to update the catalog with new texts from source and templates (file tr_update.py):
#!flask/bin/python
import os
import sys
if sys.platform == 'win32':
pybabel = 'flask\\Scripts\\pybabel'
else:
pybabel = 'flask/bin/pybabel'
os.system(pybabel + ' extract -F babel.cfg -k lazy_gettext -o messages.pot app')
os.system(pybabel + ' update -i messages.pot -d app/translations')
os.unlink('messages.pot')
And finally, a script to compile the catalog (file tr_compile.py):
#!flask/bin/python
import os
import sys
if sys.platform == 'win32':
pybabel = 'flask\\Scripts\\pybabel'
else:
pybabel = 'flask/bin/pybabel'
os.system(pybabel + ' compile -d app/translations')
These scripts should make working with translation files an easy task.
Final words
Today we have implemented an often overlooked aspect of web applications. Users want to work in their native language, so being able to publish our application in as many languages as we can find translators for is a huge accomplishment.
In the next article we will look at what is probably the most complex aspect in the area of I18n and L10n, which is the real time automated translation of user generated content. And we will use this as an excuse to add some Ajax magic to our application.
Here is the download link for the latest version of microblog, including the complete Spanish translation:
Download microblog-0.14.zip.
If you prefer, you can also find the code on github here.
Thank you for being a loyal reader. See you next time!
Miguel
Origin: http://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-xiv-i18n-and-l10n